What is MVCC (Multi-Version Concurrency Control) in PostgreSQL
In Concurrency Control theory, there are two ways you can deal with conflicts:
- You can avoid them, by employing a pessimistic locking mechanism (e.g. Read/Write locks, Two-Phase Locking)
- You can allow conflicts to occur, but you need to detect them using an optimistic locking mechanism (e.g. logical clock, MVCC)
Because MVCC (Multi-Version Concurrency Control) is such a prevalent Concurrency Control technique (not only in relational database systems, in this article, I’m going to explain how it works.
What’s the goal
When the ACID transaction properties were first defined, Serializability was assumed. And to provide a Strict Serializable transaction outcome, the 2PL (Two-Phase Locking) mechanism was employed. When using 2PL, every read requires a shared lock acquisition, while a write operation requires taking an exclusive lock.
- a shared lock blocks Writers, but it allows other Readers to acquire the same shared lock
- an exclusive lock blocks both Readers and Writers concurring for the same lock
However, locking incurs contention, and contention affects scalability. The Amdhal’s Law or the Universal Scalability Law demonstrate how contention can affect response Time speedup.
For this reason, database researchers have come up with a different Concurrency Control model which tries to reduce locking to a bare minimum so that:
- Readers don’t block Writers
- Writers don’t block Readers
The only use case that can still generate contention is when two concurrent transactions try to modify the same record since, once modified, a row is always locked until the transaction that modified this record either commits or rolls back.
In order to specify the aforementioned Reader/Writer non-locking behavior, the Concurrency Control mechanism must operate on multiple versions of the same record, hence this mechanism is called Multi-Version Concurrency Control (MVCC).
While 2PL is pretty much standard, there’s no standard MVCC implementation, each database taking a slightly different approach. In this article, we are going to use PostgreSQL since its MVCC implementation is the easiest one to visualize.
PostgreSQL
While Oracle and MySQL use the undo log to capture uncommitted changes so that rows can be reconstructed to their previously committed version, PostgreSQL stores all row versions in the table data structure.
What’s even more interesting is that every row has two additional columns:
– which defines the transaction id that inserted the record
– which defines the transaction id that deleted the row
In PostgreSQL, the Transaction Id is a 32-bit integer, and the VACUUM process is responsible (among other things like reclaiming old row versions that are no longer in use) for making sure that the id does not overflow.For this reason, you should never disable the VACUUM as transaction wraparound can lean to catastrophic situations.
Inserting a record
To understand how INSERT works in MVCC, consider the following diagram:

- Both Alice and Bob start a new transaction, and we can see their transaction ids by calling the
txid_current()PostgreSQL function - When Alice inserts a new
postrow, the - Under default Read Committed isolation level, Bob cannot see Alice’s newly inserted record until Alice committs her transaction
- After Alice has committed, Bob can now see Alice’s newly inserted row
If the transaction id is higher than thevalue of a committed row, the transaction is allowed to read this record version.
If the transaction id is lower than the
Deleting a record
To understand how DELETE works in MVCC, consider the following diagram:

- Both Alice and Bob start a new transaction, and we can see their transaction ids by calling the
txid_current()PostgreSQL function - When Bob deletes a
postrow, the - Under default Read Committed isolation level, until Bob manages to commit his transaction, Alice can still see the record that was deleted by ob
- After Bob has committed, Alice can no longer see the deleted row
While in 2PL, Bob’s modification would block Alice read statement, in MVCC Alice is still allowed to see the previous version until Bob manages to commit his transaction.
The DELETE operation does not physically remove a record, it just marks it as ready for deletion, and the VACUUM process will collect it when this row is no longer in use by any current running transaction.
If the transaction id is greater than thevalue of a committed row, the transaction is not allowed to read this record version anymore.
If the transaction id is lower than the
Updating a record
To understand how UPDATE works in MVCC, consider the following diagram:
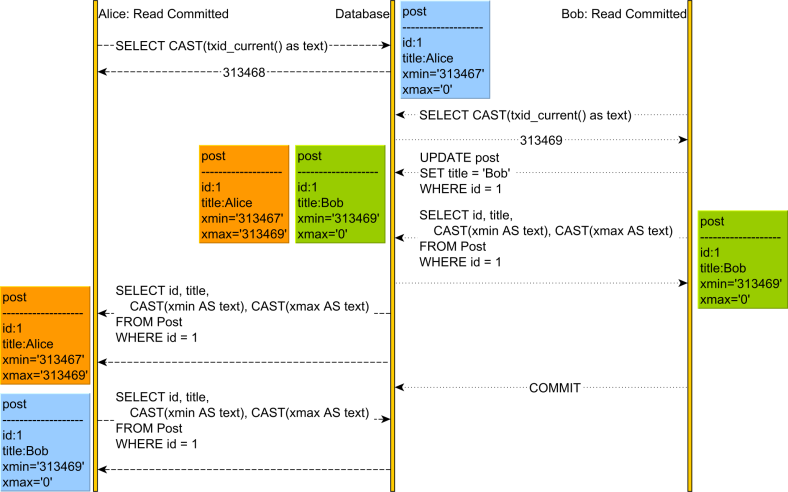
- Both Alice and Bob start a new transaction, and we can see their transaction ids by calling the
txid_current()PostgreSQL function - When Bob updates a
postrecord, we can see two operations happening: a DELETE and an INSERT.
The previous row version is marked as deleted by setting the - Under default Read Committed isolation level, until Bob manages to commit his transaction, Alice can still see the previous record version
- After Bob has committed, Alice can now see the new row version that was updated by BobConclusion
By allowing multiple versions of the same record, there is going to be less contention on reading/writing records since Readers will not block writers and Writers will not block Readers as well.
Although not as intuitive as 2PL (Two-Phase Locking), MVCC is not very difficult to understand either. However, it’s very important to understand how it works, especially since data anomalies are treated differently than when locking is being employed.
Conclusion
By allowing multiple versions of the same record, there is going to be less contention on reading/writing records since Readers will not block writers and Writers will not block Readers as well.
Although not as intuitive as 2PL (Two-Phase Locking), MVCC is not very difficult to understand either. However, it’s very important to understand how it works, especially since data anomalies are treated differently than when locking is being employed.


Comments
Post a Comment